ParallelReasoning: An interesting approach to Chain-of-Thought
ParallelReasoning is a reasoning model built to test how far chain-of-thought reasoning can be pushed. It combines multiple instances of Google's Gemma 3 (27b parameters) to generate the reasoning processes, and achieves performance getting close to o3 or o4-mini.
Unlike other reasoning models, ParallelReasoning runs multiple instances of Gemma 3 in parallel, each independently attempting to reason through the same prompt. Through aggregation and refinement, it produces a more complete and stable response than normal chain-of-thought models.
Architecture
ParallelReasoning is organized into three distinct layers:
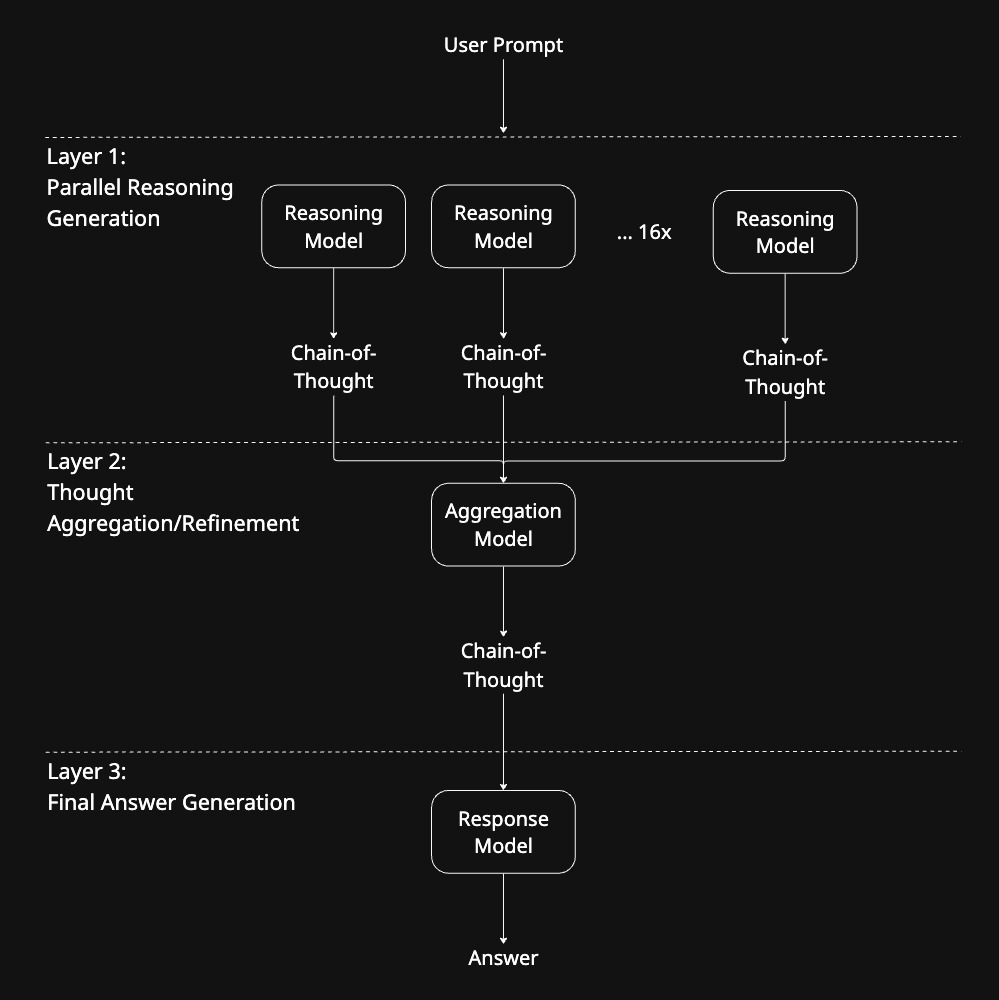
- Layer 1: Parallel Reasoning Generation
16 independent Gemma 3 models run the user prompt in parallel. Each instance generates a full, independent chain-of-thought — not a final answer, but a structured reasoning process attempting to reach one. - Layer 2: Reasoning Aggregation and Refinement
This layer consolidates the various reasoning outputs. It identifies the more common reasoning steps across different chains, filters out random hallucinations, and merges the most promising reasoning paths into a final, refined chain-of-thought. - Layer 3: Final Answer Generation
The final layer takes the refined reasoning along with the original prompt and generates the final output to the user.
(In the "mini" version of the model, Layers 2 and 3 are combined into a single step for faster reasoning. Additionally, the "mini" model uses 6 parallel instances in Layer 1, compared to 16 in the full version.)
Parallel Reasoning Benefits
By generating multiple chains-of-thought independently, ParallelReasoning addresses a weakness in traditional LLMs: early reasoning bias. In a traditional chain-of-thought model, a small mistake early in the reasoning often leads to compounding errors. Here, each model begins its chain without influence from the others, allowing different reasoning paths to explore different directions. The refinement/aggregation layer then selects the most promising trajectories.
This massively parallel approach ends up generating between 20,000 and 80,000 tokens during the reasoning phase — far more than other reasoning models like DeepSeek R1 typically produce (around 4,000 reasoning tokens). Thanks to parallelization, this deeper thinking does not lead to proportionally higher latency.
Results and Comparisons
From my informal testing, ParallelReasoning has surprisingly demonstrated reasoning quality approaching top reasoning models like O3 and O4-mini, despite starting from a small base model (Gemma 3 at 27B parameters).
While traditional reasoning models are constrained by latency and context length available for reasoning generation, ParallelReasoning achieves broader reasoning by generating a significantly higher volume of tokens.
Fun fact: I "vibe coded" the entire website where the model is deployed (a ChatGPT-like interface), exclusively using this model. ;)
Demo Versions
The demonstration website offers two models:
- ParallelReasoning
Full version with 16 parallel Gemma 3 instances at Layer 1, followed by refinement/aggregation and final answer generation. - ParallelReasoning-mini
Lightweight version with 6 Gemma 3 instances at Layer 1, and a simplified two-layer process combining refinement/aggregation and answer generation into a single step.
Current Status
ParallelReasoning is currently available for public demo on this site.
It began as a pet project and led to interesting results, so I believe it is worth sharing ;) If you have any doubts or suggestions, feel free to reach out to me! rodolfo43393@gmail.com
Try the Model